Machine
Learning
Modell- und Datentypen
Vorgehen

Fortschritt

Hörsaalfrage
Welche Ebenen hat die Wissenspyramide?

Wissenspyramide
Die Wissenspyramide ist ein Modell zur Darstellung der Entstehung von Wissen. Die vier Elementtypen: Zeichen, Daten, Informationen und Wissen werden pyramidenförmig als 4 Ebenen dargestellt, wobei die Zeichen die Basis und das Wissen die Spitze der Pyramide bilden.

Hörsaalfrage
Welche Schritte muss man beim Maschinellem Lernen durchlaufen?
Vorgehensweise im Maschinellem Lernen

Typische Vorgehensweise beim Maschinellem Lernen
Datenexploration
In diesem Schritt werden die Daten eingehend untersucht, um ein besseres Verständnis für ihre Struktur, Eigenschaften und Muster zu erhalten. Häufige Aufgaben umfassen die Analyse von Verteilungen, Korrelationen zwischen Variablen, das Identifizieren von Ausreißern und das Visualisieren der Daten mittels Diagramme oder Grafiken. Ziel ist es, Einblicke in die Daten zu gewinnen, die für die Modellierung relevant sind, sowie potenzielle Probleme oder Herausforderungen zu identifizieren, die angegangen werden müssen.
Vorgehensweise im Maschinellem Lernen
Typische Vorgehensweise beim Maschinellem Lernen
Datenbereinigung
In diesem Schritt werden die Daten bereinigt und vorverarbeitet, um sicherzustellen, dass sie für das Modelltraining geeignet sind. Dies beinhaltet Aufgaben wie das Entfernen fehlender oder unvollständiger Daten, das Behandeln von Ausreißern, das Skalieren von Merkmalen und das Codieren kategorialer Variablen. Ziel ist es, qualitativ hochwertige Daten bereitzustellen, die frei von Störungen oder Verzerrungen sind und eine reibungslose Modellierung ermöglichen.
Vorgehensweise im Maschinellem Lernen
Typische Vorgehensweise beim Maschinellem Lernen
Modellauswahl
In diesem Schritt werden geeignete Modelle ausgewählt, die für das spezifische Problem am besten geeignet sind, sowie relevante Merkmale, die zur Vorhersage beitragen. Dies kann durch die Bewertung verschiedener Modelle und Merkmalskombinationen anhand von Leistungsmetriken oder durch den Einsatz von Techniken wie Feature Importance oder Cross-Validation erfolgen. Ziel ist es, das beste Modell und die am besten geeignete Merkmale auszuwählen, um genaue und robuste Vorhersagen zu ermöglichen.
Vorgehensweise im Maschinellem Lernen
Typische Vorgehensweise beim Maschinellem Lernen
Modelltraining
In diesem Schritt wird das ausgewählte Modell auf den Trainingsdaten trainiert, um die Beziehung zwischen den Eingangsmerkmalen und den Zielvariablen zu lernen. Das Modell wird durch Anpassen seiner Parameter an die Trainingsdaten verbessert, wobei ein Optimierungsalgorithmus wie Gradientenabstieg verwendet wird. Ziel ist es, ein Modell zu entwickeln, das die Trainingsdaten gut generalisiert und in der Lage ist, genaue Vorhersagen für neue, unbekannte Daten zu treffen.
Vorgehensweise im Maschinellem Lernen
Typische Vorgehensweise beim Maschinellem Lernen
Modellvalidierung
Nach dem Training wird das Modell mit Testdaten validiert, um seine Leistung zu bewerten und zu überprüfen, wie gut es auf neue Daten generalisiert. Die Vorhersagen des Modells werden mit den tatsächlichen Werten verglichen, um die Genauigkeit und Zuverlässigkeit des Modells zu überprüfen. Ziel ist es, sicherzustellen, dass das Modell robust ist und konsistente Leistung über verschiedene Datensätze und Umgebungen bietet.
Vorgehensweise im Maschinellem Lernen
Typische Vorgehensweise beim Maschinellem Lernen
Modellanwendung
Nach erfolgreicher Validierung wird das trainierte Modell in eine Produktionsumgebung implementiert, wo es zur Vorhersage auf Echtzeitdaten angewendet wird. Dies kann die Integration des Modells in Softwareanwendungen, Webdienste oder andere Systeme umfassen. Ziel ist es, das Modell in einer Umgebung bereitzustellen, in der es praktische Anwendungen hat und kontinuierlich genutzt werden kann.
Hörsaalfrage
Welcher Schritt ist der Zeitaufwändigste?
Die Herausforderung von ML
Datenaufbereitung ist der zeitaufwändigste (80%) und wenig herausforderndste langweiligste (76%) Schritt bei der Datenanalyse.1
Die digitale Transformation besteht zu 80 % aus Menschen, zu 20 % aus Technologie: Domänenwissen ist von entscheidender Bedeutung, und daher der Bedarf an Experten, die das Geschäft verstehen und über das notwendige Wissen verfügen, um die richtigen Fragen zu stellen und die Antworten zu kontextualisieren. 2

Vorgehensweise im Maschinellem Lernen
Die Datenanalyse in der Praxis geschieht meist nicht sequentiell, sondern man iteriert meist agil zu der richtigen Lösung. Das umfasst mehrmaliges Bereinigen der Daten, Überdenken der Modellauswahl und mehrmaliges Modell-Training und Modellvalidierung bevor das richtige Modell gefunden wird.

Tools

Jupyter Notebooks
- Interaktive Entwicklungsumgebung zum schrittweisen Ausführen von Code
- Agile, iterative Entwicklung von ML-Modellen
- Speichert die Ausgaben von Code wie Textausgaben und Visualisierungen
- Ergebnisse sichtbar und belegt
- Ablauf der ML-Modellgenerierung ist belegt und kann wiederholt werden
- Ablauf wiederholbar
- Kann um Texte und Bilder in Markdown erweitert werden
- Erklärungen helfen Verständnis
- Kann dadurch einfach geteilt und gemeinsam bearbeitet werden
- Einfache Kommunikation
Python ist die Sprache für Data Science und KI
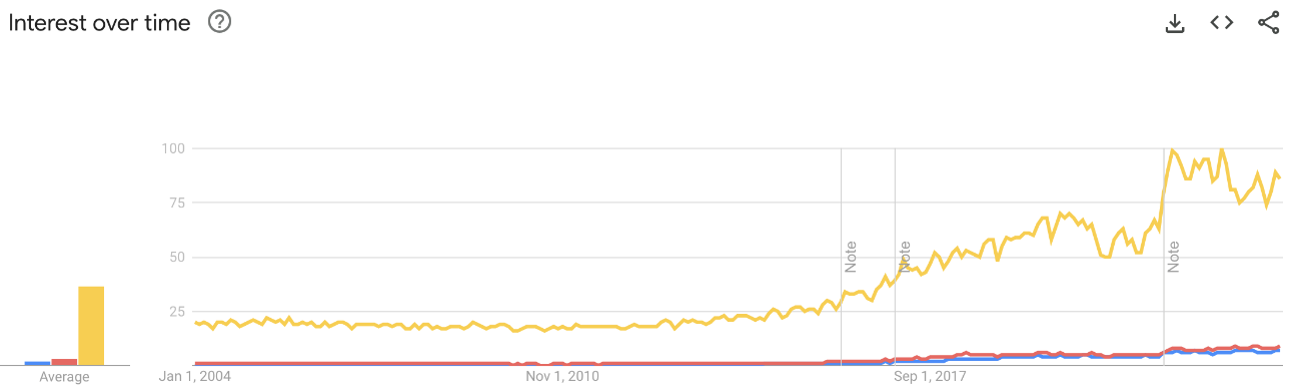
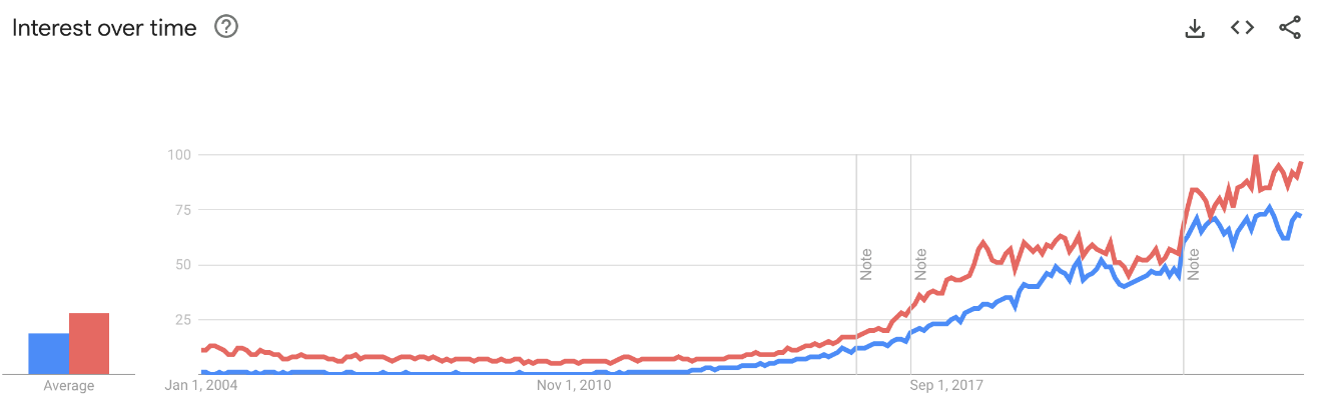
Python wird in Data Science zum Maschinellen Lernen sehr oft verwendet. Sie hat sehr viele Bibliotheken zur Analyse von Daten. Heutzutage gibt es in Python Bibliotheken für fast jedes Anwendungsgebiet.
Python
Entworfen: 1991
Auf Lesbarkeit ausgelegt
The Zen of Python (PEP 20):
- Beautiful is better than ugly
- Explicit is better than implicit
- Simple is better than complex
- Complex is better than complicated
- Readability counts

Python Bilbiotheken
![]()
Numpy ist die führende Bibliothek in Python für Vektor- und Matrixberechnungen. Daten und Berechnungen werden dabei nicht in Python sondern mit optimierten C-Objekten und Operationen ausgeführt. Es ist besonders gut für rein numerische Analysen wie lineare Algebra geeignet.
![]()
Pandas ist die wichtigste Python-Bibliothek für die Arbeit mit Tabellen (Dataframes). Pandas nutzt intern Numpy (Vektoren und Matrizen) fügt aber Tabellenkonzepte hinzu (Spaltennamen, Zeilenindizes, Aggregationsoperatoren, etc.).
![]()
scikit-learn ist eine der wichtigsten Bibliotheken für traditionelles maschinelles Lernen in Python ohne spezifischen Fokus auf Neuronale Netzwerke. Es basiert intern auf Numpy und SciPy, welches viele Algorithmen für lineare Algebra implementiert.
![]()
Plotly ist eine Bibliothek zur Erstellung interaktiver Diagramme, die sehr einfach zu benutzen ist. Es können damit einfache Diagramme erzeugt werden bis zu ganzen Benutzeroberflächen. Es nutzt modern Webtechnologien (JavaScript) zur Visualisierung.
Klassen von
ML-Modellen
Überwachtes Lernen, en. Supervised Learning
Die Modelle benötigen vorher gelabelten Beispieldaten, die vorgeben, wie das Ergebnis aussehen soll. Beim Labeln weißt man den Daten, die zu erlernenden Kategorien zu. Das ML-Modell lernt welche Elemente zu welchen Kategorien gehören.
- Gut wenn man die Kategorien kennt und gelabelte Daten zum Trainieren hat.

Überwachtes Lernen Arten und Anwendungen

Unüberwachtes Lernen, en. Unsupervised Learning
Die Modelle benötigen keine gelabelten Beispieldaten zum Lernen, sondern identifizieren Strukturen in den Daten. Das ML-Modell lernt selbst die Elemente zu unterscheiden, kennt aber nicht den semantischen Namen der Cluster.
- Gut wenn man die Kategorien nicht kennt oder keine gelabelten Daten hat.

Unüberwachtes Lernen Arten und Anwendungen

Selbstüberwachtes Lernen, en. Self-supervised Learning
Die Modelle erzeugen selbst gelabelte Trainingsdaten mit einem vortrainierten, internen Generatormodell. Dieses ist einfacher und wird meist supervised vortrainiert und braucht dadurch weniger Trainingsdaten als reine supervised Modelle.
- Gut wenn ein einfacheres Generatormodell zum Vortraining erzeugbar ist.

Selbstüberwachtes Lernen Arten und Anwendungen

Verstärkendes Lernen, en. Reinforcement Learning
Die Modelle werden durch Belohnung trainiert, die angibt, ob ein Ergebnis gut oder schlecht ist. Das Modell lernt aus der Belohnung welche Elemente in welche Kategorie gehören.
- Gut wenn man die Kategorien nicht genau kennt, aber bewerten (und belohnen) kann, welche Entscheidungen tendenziell besser oder schlechter sind.

Verstärkendes Lernen Arten und Anwendungen

Datenklassen

Strukturiert


Unstrukturiert

Lorem ipsum dolor sit amet, consetetur sadipscing elitr, sed diam nonumy eirmod tempor invidunt ut labore et dolore magna aliquyam erat, sed diam voluptua. At vero eos et accusam et justo duo dolores et ea rebum. Stet clita kasd gubergren, no sea takimata sanctus est Lorem ipsum dolor sit amet.
Texte werden im Computer als Zeichenfolge gespeichert (Kontext). Der Computer erkennt zwar Worte (Syntax), aber nicht deren Bedeutung (Semantik).
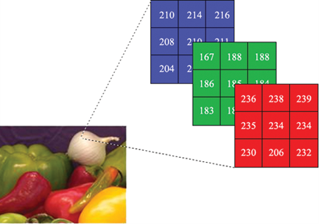
Bildern werden im Computer als Pixel-Matrix gespeichert (Kontext). Die Farbe in jedem wird dann als Zahl in RGB gespeichert (Syntax). Aber wir kennen nicht die Semantik.
Semi-Strukturiert

JSON wird im Computer als Zeichenfolge gespeichert und verbindet verschiedene Daten in einem Objekt (Kontext). Die Objekte folgen zwar einer gewissen Struktur (Syntax) können aber davon abweichen und unstrukturierte Elemente, wie Text enthalten.

IFC-Dateien (CAD/BIM) sind Textdateien aus denen ein Objektgraph aufgebaut wird (Kontext). Es gibt den definierten Syntax und die Semantik der IFC-Tags selbst, aber kein Semantik für enthaltene Bezeichner (z.B. Raumtypen).
Datenklassen
Hörsaalfrage
Welche Datentypen gibt es in Programmiersprachen?

Datentypen

Datentypen
Definition: Datentyp
Der Datentyp gibt an, von welcher Art die Daten sind, die mit ihm beschrieben werden (Datenvereinbarung), und welche Operationen auf diesen ausgeführt werden können.

Hörsaalfrage
Welche Datentypen gibt es in Python?

Datentypen in Python
Python vereinfacht die Datentypen auf einige wenige Typen und weist die Typen dynamisch zu. Das ist einfach zu benutzen, aber bei vielen Berechnungen nicht sehr performant.

Datentypen in Numpy
Numpy führt explizite Datentypen ein, damit Berechnungen deutlich performanter durchgeführt werden können, dies wird erzielt durch optimierte Speicherdarstellung, Vermeidung von Konvertierungen und effizienten Rechnungen in C.

Datentypen in Pandas
Pandas nutzt die Basisdatentypen von Numpy führt allerdings Serien und Tabellen (Dataframe) ein, damit Berechnungen deutlich performanter durchgeführt werden können, dies wird erzielt durch optimierte Speicherdarstellung, Vermeidung von Konvertierungen und effizienten Rechnungen in C.

f r a g e n ?