Machine
Learning
Herausforderungen
Fortschritt

Evaluation

Hörsaalfrage
Welche Schritte muss man beim Maschinellem Lernen durchlaufen?
Hörsaalfrage
Welcher Schritt ist der Zeitaufwändigste?
Die Herausforderung von ML
Datenaufbereitung ist der zeitaufwändigste (80%) und wenig herausforderndste langweiligste (76%) Schritt bei der Datenanalyse.1
Die digitale Transformation besteht zu 80 % aus Menschen, zu 20 % aus Technologie: Domänenwissen ist von entscheidender Bedeutung, und daher der Bedarf an Experten, die das Geschäft verstehen und über das notwendige Wissen verfügen, um die richtigen Fragen zu stellen und Antworten zu kontextualisieren.2

Vorgehensweise im Maschinellem Lernen

Die Datenanalyse in der Praxis geschieht meist nicht sequentiell, sondern man iteriert meist agil zu der richtigen Lösung. Das umfasst mehrmaliges Bereinigen der Daten, Überdenken der Modellauswahl und mehrmaliges Modell-Training und Modellvalidierung bevor das richtige Modell gefunden wird.

Skallierbarkeit

Skallierbarkeitsprobleme
Big Data: Es werden mehr Daten erzeugt als gespeichert kann (z.B. Telekommunikation), bzw. bewegt werden kann (z.B. Satelliten).

Big Model: Modelle (z.B. LLM) sind zu groß, um sie zu bewegen bzw. die Berechnung zu aufwändig für einzelne Rechner.

Many Models: Es werden sehr viele spezifische Modelle erzeugt (z.B. Energievorhersage, Anomalierkennung).

Partitionierung
Bei der Partitionierung wird eine Berechnung in kleinere, überschaubare Teilberechnungen zerlegt, die unabhängig voneinander (parallel) auf unterschiedlichen Teilen des Datensatzes berechnet werden. Dies ist besonders nützlich für Algorithmen die in Teilen berechnet und dann Aggregiert werden können (Statistiken, Lineare Regression, k-Means, Random Forest, SVM, PCA, KNN).
Wichtige Frameworks zur Parallelisierung sind dask und Spark.

Verteiltes Rechnen großer Modelle
Verteiltes Rechnen eines großen Modells ist eine Erweiterung der Partitionierung, bei der die Ausführung auf mehreren Rechenknoten (z.B. Cloud-PCs) verteilt werden, um die Effizienz und Geschwindigkeit zu erhöhen. Das bedeutet auch dass die Daten mit der Berechnung eines großen Modells auf die Rechenknoten verteilt werden müssen, was wiederum Performance-Nachteile mit sich bringen kann.
Typische Frameworks sind Hadoop und Spark die den MapReduce-Algorithmus (Dean and Ghemawat 2008) nutzen.

Verteiltes Rechnen vieler Modelle
Beim verteiltem Rechnen vieler Modelle werden mehrere Modelle parallel trainiert. Diese nutzen meist unterschiedliche, z.T. überschneidende Datensätze. Die Aufgabe besteht darin die Daten und die Berechnungen über mehreren Rechenknoten in der Cloud zu verteilen. Zur Lastverteilung werden meist Joblisten genutzt.
Frameworks zum verteilten Rechnen sind Ray für Python Modelle, was wir bereits beim Reinforcement Learning genutzt haben, oder Airflow.

Stream-Processing
Sind die Daten zu Groß zum speichern, nutzt man mein Stream-Processing. Dabei werden die Datenströmen in Echtzeit kontinuierlich verarbeitet und nur die Ergebnisse und Modelle gespeichert. Werden die Modelle dabei kontinuierlich geupdated so spricht man auch vom Online Learning. Das eignet sich besonders zur Datenaggregation (Statistiken), Mustererkennung (Anomalien), oder Vorhersagen mit hohen Echtzeitanforderungen (Short-Term-Trading).
Ein typisches Framework für Stream-Processing ist Kafka oder Flink.

from kafka import KafkaConsumer
import json
# Kafka-Consumer erstellen
consumer = KafkaConsumer('test-topic')
# Nachrichten vom Topic lesen und verarbeiten
for message in consumer:
# Verarbeitung der empfangenen Nachrichten
print(f"Received message: {message.value}")
# Kafka-Consumer schließen
consumer.close()Edge Computing
Beim Edge Computing werden die Daten bereit dort verarbeitet wo sie entstehen, also direkt auf den lokalen Geräten. Dadurch hat man schneller Ergebnisse und höheren Datenschutz. Das eignet sich insbesondere für Probleme wo nur lokale Modelle (z.B. Energievorhersage, Anomalieerkennung, etc.) benötig werden und globale Modelle vereinfacht nur angewendet werden, z.B. mit Tensorflow Lite.

import tensorflow as tf
# Modell für Edge Computing konvertieren
# converter = tf.lite.TFLiteConverter.from_keras_model(model)
# tflite_model = converter.convert()
# with open('model.tflite', 'wb') as f: f.write(tflite_model)
# TFLite-Modell auf Edge-Geräten ausführen
interpreter = tf.lite.Interpreter(model_path="model.tflite")
interpreter.allocate_tensors()
# Input und Output Tensor definieren
input_tensor = interpreter.tensor(interpreter.get_input_details()[0]['index'])
output_tensor = interpreter.tensor(interpreter.get_output_details()[0]['index'])
# Beispiel-Inferenz auf Edge-Gerät durchführen
input_tensor()[0] = input_data
interpreter.invoke()
print(output_tensor()[0])Federated Learning
Federated Learning erweitert das Edge Computing zum Training von gemeinsamen Modellen über verteilte Geräte, ohne dass die Daten zentralisiert werden müssen. Dabei wird lokal ein gemeinsames Modell weiter trainiert und Änderungen synchronisiert, so dass das gemeinsame Modell sich verbessert.
Hier können Frameworks wie PySyft oder Tensorflow Federated genutzt werden.

import tensorflow as tf
import tensorflow_federated.learning as tffl
# Federated Learning-Modell definieren
def create_federated_model():
return tf.keras.models.Sequential([
tf.keras.layers.Dense(10),
tf.keras.layers.Dense(1)
])
# TensorFlow Federated Konfiguration erstellen
fed_avg = tffl.build_federated_averaging_process(
model_fn=create_federated_model)
# Modell trainieren
initial_state = fed_avg.initialize()
for round_num in range(10):
state, metrics = fed_avg.next(state, client_data)
print('Round {}: loss={}'.format(round_num, metrics.loss))Datenschutz

Anonymisierung

Fairness
Beispiel: Google image search – Bad vs Good Hair
Unprofessional Hair for Work


Beispiel: COMPAS - Rückfälligkeit von Straftätern
- COMPAS wird seit 2004 zur Bewertung der Rückfälligkeit von Straftätern genutzt um Strafhöhe und -dauer festzulegen
- 2016 wiesen KI-Forscher nach, dass die Risikobewertung für dunkelhäutige Menschen meist doppelt so hoch ist (Angwin et al. 2022)
- Algorithmus ist proprietär

Beispiel: Schufa
Schufa Score - Schätzwert für die Wahrscheinlichkeit, dass ein Kredit bedient wird
Algorithmus ist proprietär
2018 formte sich OpenSchufa-Projekt welches durch Selbstauskunft versucht hat den Schufa Algorithmus zu testen
Ergebnisse zeigen, dass Geschlecht, Alter und andere Faktoren den Score beeinflussen – z.B. werden junge Männer eher schlecht bewert, auch ohne negative Geschichte

Digitalisierung der Kreditwürdigkeit
Manueller Ansatz in der Vergangenheit

Digitaler Ansatz

Das Problem mit dem Bias

Die drei Ansätze
Fairness der Daten Durch Vorverarbeitung kann man versuchen gezielt den Bias aus den Trainingsdaten zu entfernen.
Fairness der ML Modelle Spezielle Modelle erlauben es die sensitiven Daten verstärkt zu ignorieren.
Fairness des Ergebnisse Bestimmte Tests und Algorithmen Bewerten die Fairness von Modellen und ggf. widerrufen Ergebnisse.
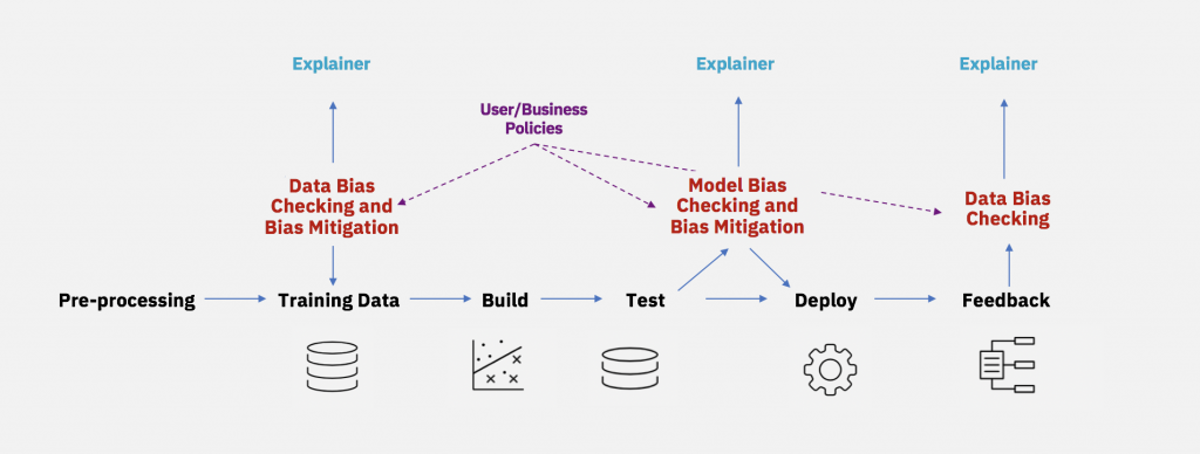
Fairness der Daten verbessern
- Komplettes Entfernen sensibler Merkmale wenn möglich. Oft sind Merkmale aber korreliert und schwer zu entfernen.
- Ausprägungen der Merkmale sollte repräsentativ sein und alle Varianten enthalten ohne Ausschluß oder Bevorzugung
- Umgewichtung von Varianten verhindert, dass Ausprägungen dominieren
- Beim Sampling von Traings-daten achtet man darauf, das immer verschiedene Varianten vertreten sind

Fairness der Modelle
- Im Training wird das Modell durch Kostenfunktionen bestraft, wenn es sensible Merkmale benutzt.
- Z.B. werden spezielle Adversarial Debiasing KNN Modelle eingesetzt, die gezielt darauf trainiert sind eine Vorhersage \(Y\) zu treffen ohne die sensiblen Merkmale \(Z\) zu lernen

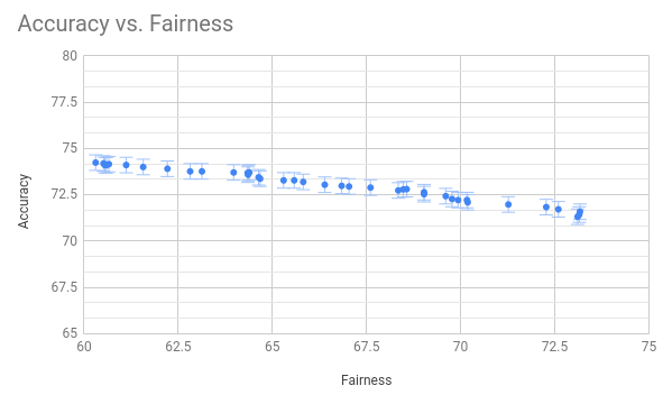
Genauigkeit vs. Fairness
- Verbesserte Fairness führt normalerweise zu einer reduzierten Vorhersagegenauigkeit der Modelle
- Genauigkeit wird oft überbewertet!
- In vielen praktischen Anwendungen ist es sinnvoll eher etwas Genauigkeit zu verlieren und dafür auf Fairness, Robustheit und Angriffssicherheit der Modelle zu achten.
Ausblick

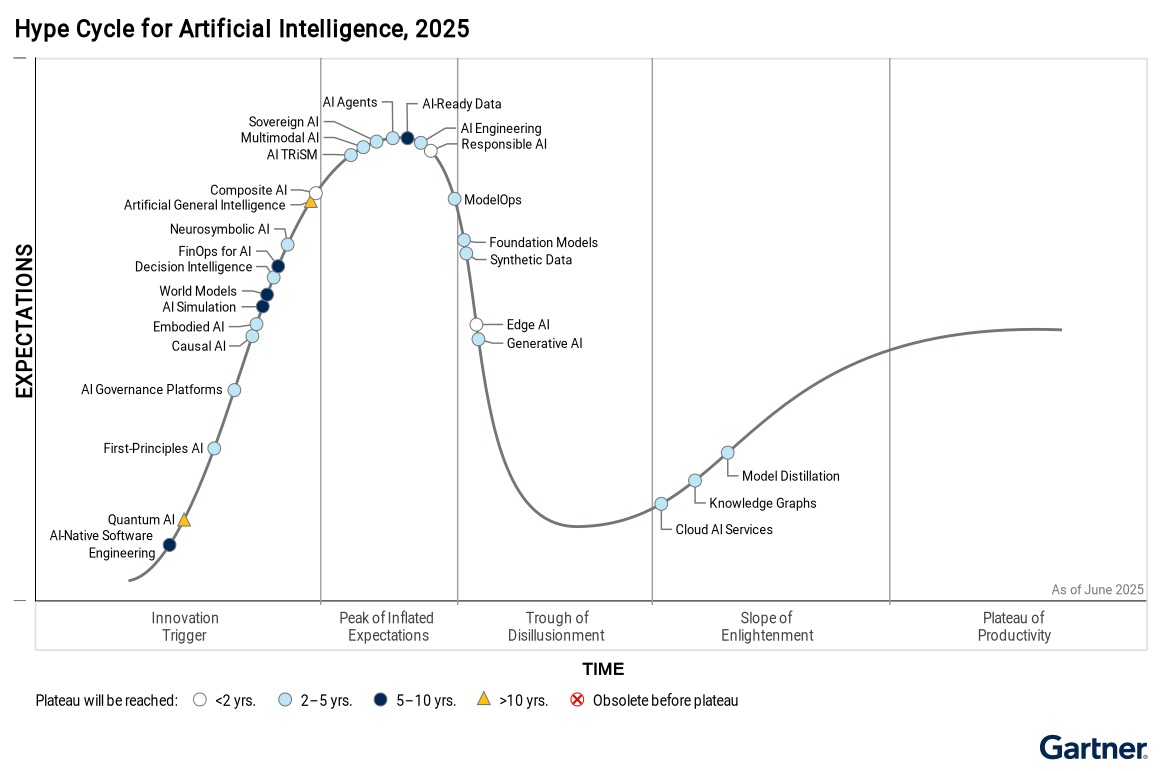
AI Hype
- Generative AI
- Foundation Models
- AI Agents
- Multimodale AI
- Neurosymbolik AI
- Kausale AI
Maschinelles Lernen und Künstliche Intelligenz
- Grundlagen Neuraler Netzwerke
- Einführung in Deep Neural Networks
- Architekturen Neuronaler Netzwerke (z.B. ANN, CNN, DNN, LSTM, Transformer, GNN)
- Einführung in Foundation Models
Zeit: Wintersemester 2024
