Generalisierte Regression#

Das Leben ist die Summe all unserer Entscheidungen
— Albert Camus
Folien#
Generalisierte Lineare Modelle#
Generalisierte Lineare Modelle (GLM) sind eine Verallgemeinerung der Linearen Modelle, die wir bereits kennen gelernt haben. Dadurch lassen sich zum Beispiel Lineare Regressionsmodelle und Logistische Regressionsmodelle kombinieren. Sie folgt im Wesentlichen der Idee, die wir schon bei der logistischen Regression kennen gelernt haben, dass wir eine lineare Basisfunktion \(z_i\) haben:
GLMs sind flexibel und erlauben den Einsatz verschiedener Zielverteilungen, das ist besonders wichtig, wenn klassische lineare Regression ungeeignet ist. Sie bilden oft die Grundlage für Klassifikations- und Regressionsmodelle in ML-Bibliotheken wie statsmodels oder scikit-learn.
die wir über eine Verknüpfungsfunktion \(g(z_i)\) in eine Vorhersage unserer Zielvariable \(\hat z_i\) transformieren
Die Verknüpfungsfunktion übersetzt das lineare Modell (z.B. eine Temperatur-Zeit-Funktion) in die passende Skala der Zielgröße, wie zum Beispiel Wahrscheinlichkeiten, Zählwerte oder logarithmierte Kosten.
Diese Verknüpfungsfunktion kann eine Sigmoid-Funktion sein (Logistische Regression - Ob ein Betonbauteil unter Last versagt (Ja/Nein), eine Exponential-Funktion (Poisson Regression - Wie viele Fahrzeuge über eine Brücke pro Stunde fahren), eine Gamma-Funktion (Gamma Regression - Prognose von Baukosten oder Materialverbrauch) oder eine unveränderte \(z_i\) (Lineare Regression). Das erlaubt je nach Verteilungstyp der Zielvariable Eingangswerte zu transformieren, die anderen Verteilungen folgen und somit Variablen, die eigentlich andere Verteilungsformen haben in einem Vorhersagemodell kombinieren. Somit muss der Vorhersagefehler \(\varepsilon\) auch nicht mehr Normalverteilt sein, sondern kann andere Verteilungsformen annehmen.
Das Entscheidende hierbei ist, dass die Basisfunktion \(z_i\) immer noch linear ist und nur transformiert wird, das bedeutet, dass wenn sich die unabhängigen Variable \(x_{k,i}\) ändert, sich auch die abhängige Variable \(y_i\) ändert, unabhängig vom Wert der anderen unabhängigen Variablen.
Die Koeffizienten \(\beta_0, \beta_1, \ldots, \beta_n\) werden auch hier durch die schon diskutierte Maximum-Likelihood-Schätzung (MLE) bestimmt und zum Beispiel durch das Newtonverfahren iterativ angenähert.
Generalisierte Additive Modelle#
Bisher wurde immer eine Lineare Beziehung zwischen den Eingangsvariablen und der Zielvariable angenommen. Das sorgt für Modelle mit einfach zu verstehenden Parametern \(\beta_0, \beta_1, \ldots, \beta_n\). Dadurch sind die Modelle einfach zu berechnen und auch Praktikern gut zu erklären.
Allerdings ist die Annahme eines linearen Zusammenhanges für viele praktische Szenarien nicht immer haltbar, da z.B. in der Physik nichtlineare Zusammenhänge häufig vorkommen. Deshalb haben sich Generalisierte Additive Modelle (GAM) entwickelt, die die Idee der Verknüpfungsfunktion aus GLM übernehmen aber direkt auf die additiven einzelnen Elemente der linearen Gleichung anwenden. Dadurch das resultierende Modell zwar additiv, wie das lineare Modell, aber nicht notwendigerweise linear, da jede einzelne Transformationsfunktion \(s_j(x_{j,i})\) nichtlinear sein kann.
Die Schwierigkeit besteht darin die Transformationsfunktion \(s_j(x_{j,i})\) in ihren Beiträgen zu \(y_i\) zu bestimmen. Hierfür nimmt man an, dass \(s_j(x_{j,i})\) eine glatte Funktion ist (stetig und beliebig oft differenzierbar (zum Fitting)). Hierfür werden meist Spline-Funktionen benutzt.
Viele moderne Implementierungen von GAMs nutzen zum Bestimmen der Transformationsfunktionen den Ansatz der Rankreduktion(Reduced-rank Minimization), da er eine schnelle Schätzung der Parameter ermöglicht. Hierfür wird für die Transformationsfunktion angenommen, dass sie ein Spline aus \(K_j\) Basisfunktionen ist, die gegeben ist durch
wobei die \(b_{j,k}(x_j)\) bekannte Basisfunktionen sind, die in der Regel aufgrund guter Approximationseigenschaften gewählt werden (z.B. B-Splines) und die \(\beta_{j,k}\) Koeffizienten sind, die im Rahmen der Modellanpassung geschätzt werden müssen. Die Basisdimension \(K_j\) sollte dabei so gewählt werden, dass eine gute Anpassung der vorliegenden Daten zu erwarten ist, aber klein genug, um die Effizienz der Berechnung zu erhalten.
Durch ersetzen aller Transformationsfunktionen \(s_j(x_{j,i})\) durch Basisfunktionen, können diese in bekannter Weise durch Ableitung iterativ die Koeffizienten \(\beta_{j,k}\) bestimmen können.
GAM in Python mit Statsmodels#
Für GAM Modelle eignet sich insbesondere die statsmodels Bibliothek. Als Beispiel nutzen wir wieder den Energiedatensatz der Universität Rostock. Wir wollen noch einmal den Energiekonsum vorhersagen.
import pandas as pd # Import von Pandas
import plotly.express as px # Import von Plotly
egywth = pd.read_csv("../data/UROS/Energy1D_weather_clean.csv", parse_dates=[0])
egywth["Weekday"] = egywth["Date"].dt.day_name()
egywthN=egywth.dropna().copy()
egywthN.head()
| Date | EV_HT_740 | EV_NT_740 | E_AV_Lab | E_SV_Lab | ES_Lab | DATUM_DT | STATIONS_ID | MESS_DATUM | QN_3 | ... | UPM | TXK | TNK | TGK | eor | TemperaturKlasse | HeizKuehlTage | QNS_4 | QNF_4 | Weekday | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 | 2021-01-01 00:00:00+00:00 | 0.0 | 4080.0 | 1221.0 | 290.0 | 1.0 | 2021-01-01 00:00:00+00:00 | 4271.0 | 20210101.0 | 10.0 | ... | 90.0 | 3.0 | 1.1 | 0.3 | eor | Cold | Heizgradtag | nicht alle Parameter korrigiert | 5 | Friday |
| 3 | 2021-01-02 00:00:00+00:00 | 1170.0 | 2630.0 | 1243.0 | 284.0 | 2.0 | 2021-01-02 00:00:00+00:00 | 4271.0 | 20210102.0 | 10.0 | ... | 95.0 | 4.0 | 2.6 | 2.0 | eor | Cold | Heizgradtag | nicht alle Parameter korrigiert | 5 | Saturday |
| 4 | 2021-01-03 00:00:00+00:00 | 0.0 | 3750.0 | 1222.0 | 283.0 | 2.0 | 2021-01-03 00:00:00+00:00 | 4271.0 | 20210103.0 | 10.0 | ... | 81.0 | 4.6 | 2.4 | 0.8 | eor | Cold | Heizgradtag | nicht alle Parameter korrigiert | 5 | Sunday |
| 5 | 2021-01-04 00:00:00+00:00 | 3240.0 | 1110.0 | 1263.0 | 295.0 | 5.0 | 2021-01-04 00:00:00+00:00 | 4271.0 | 20210104.0 | 10.0 | ... | 84.0 | 4.4 | 3.0 | 2.4 | eor | Cold | Heizgradtag | nicht alle Parameter korrigiert | 5 | Monday |
| 6 | 2021-01-05 00:00:00+00:00 | 3470.0 | 1120.0 | 1346.0 | 299.0 | 1.0 | 2021-01-05 00:00:00+00:00 | 4271.0 | 20210105.0 | 10.0 | ... | 88.0 | 4.7 | 3.0 | 2.6 | eor | Cold | Heizgradtag | nicht alle Parameter korrigiert | 5 | Tuesday |
5 rows × 31 columns
Um ein GAM-Modell zu erzeugen, nutzen wir die GAM API von Statsmodels. Dafür müssen wir separat die B-Splines initialisieren.
import statsmodels.api as sm
from statsmodels.gam.api import GLMGam, BSplines
bs = BSplines(egywthN[['TMK', "SDK", "NM", "VPM"]], df=[4, 4, 4, 4], degree=[3, 3, 3, 3])
# Fit the GAM model
smfgam = GLMGam.from_formula(formula="ES_Lab ~ TMK + SDK + NM + VPM + Weekday", data=egywthN, smoother=bs)
smfgam = smfgam.fit()
egywthN["gam"]=smfgam.predict()
smfgam.summary()
| Dep. Variable: | ES_Lab | No. Observations: | 916 |
|---|---|---|---|
| Model: | GLMGam | Df Residuals: | 897 |
| Model Family: | Gaussian | Df Model: | 18.00 |
| Link Function: | Identity | Scale: | 140.96 |
| Method: | PIRLS | Log-Likelihood: | -3556.6 |
| Date: | Mon, 13 Oct 2025 | Deviance: | 1.2645e+05 |
| Time: | 11:07:14 | Pearson chi2: | 1.26e+05 |
| No. Iterations: | 3 | Pseudo R-squ. (CS): | 0.9994 |
| Covariance Type: | nonrobust |
| coef | std err | z | P>|z| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| Intercept | -16.9526 | 4.580 | -3.701 | 0.000 | -25.930 | -7.975 |
| Weekday[T.Monday] | -0.3399 | 1.470 | -0.231 | 0.817 | -3.220 | 2.540 |
| Weekday[T.Saturday] | -0.0973 | 1.474 | -0.066 | 0.947 | -2.986 | 2.792 |
| Weekday[T.Sunday] | 1.2628 | 1.478 | 0.855 | 0.393 | -1.633 | 4.159 |
| Weekday[T.Thursday] | -0.1677 | 1.472 | -0.114 | 0.909 | -3.053 | 2.718 |
| Weekday[T.Tuesday] | 1.0461 | 1.472 | 0.711 | 0.477 | -1.840 | 3.932 |
| Weekday[T.Wednesday] | -0.3203 | 1.476 | -0.217 | 0.828 | -3.213 | 2.573 |
| TMK | 2.3254 | 0.280 | 8.299 | 0.000 | 1.776 | 2.875 |
| SDK | 6.9210 | 0.197 | 35.082 | 0.000 | 6.534 | 7.308 |
| NM | 3.8209 | 0.459 | 8.319 | 0.000 | 2.921 | 4.721 |
| VPM | -2.1580 | 0.429 | -5.029 | 0.000 | -2.999 | -1.317 |
| TMK_s0 | 10.7403 | 9.344 | 1.149 | 0.250 | -7.574 | 29.054 |
| TMK_s1 | 21.3749 | 8.604 | 2.484 | 0.013 | 4.511 | 38.238 |
| TMK_s2 | -20.5221 | 4.429 | -4.634 | 0.000 | -29.202 | -11.842 |
| SDK_s0 | -15.3776 | 3.412 | -4.507 | 0.000 | -22.065 | -8.691 |
| SDK_s1 | -3.9177 | 4.190 | -0.935 | 0.350 | -12.130 | 4.295 |
| SDK_s2 | 8.1667 | 2.195 | 3.720 | 0.000 | 3.864 | 12.469 |
| NM_s0 | -7.3902 | 4.881 | -1.514 | 0.130 | -16.957 | 2.177 |
| NM_s1 | 8.9931 | 2.975 | 3.023 | 0.003 | 3.162 | 14.824 |
| NM_s2 | -3.0544 | 1.421 | -2.149 | 0.032 | -5.840 | -0.269 |
| VPM_s0 | -13.5880 | 8.606 | -1.579 | 0.114 | -30.455 | 3.279 |
| VPM_s1 | -12.6270 | 6.747 | -1.872 | 0.061 | -25.851 | 0.597 |
| VPM_s2 | 15.0970 | 3.274 | 4.611 | 0.000 | 8.680 | 21.514 |
Das Besondere ist, dass wir die einzelnen Transferfunktionen uns anzeigen lassen können, mit dem gewichteten Residuen des Eingangs. Dadurch bleibt das Modell erklärbar.
fig = smfgam.plot_partial(0, cpr=True)

fig = smfgam.plot_partial(1, cpr=True)
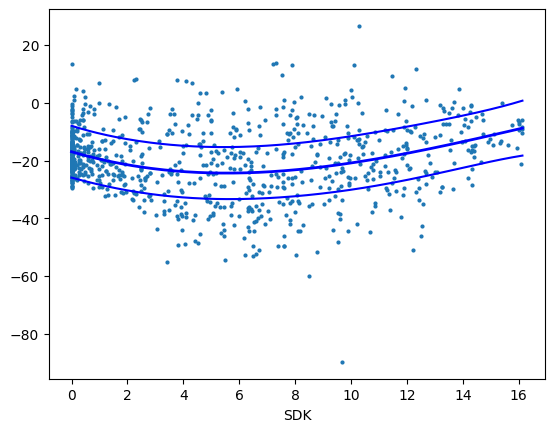
fig = smfgam.plot_partial(2, cpr=True)

fig = smfgam.plot_partial(3, cpr=True)

Vergleichen wir das mit dem alten Linearen Modell.
import statsmodels.formula.api as smf
smflm = smf.ols("ES_Lab ~ TMK + SDK + NM + VPM + Weekday", data=egywthN).fit()
egywthN["ols"]=smflm.predict()
smflm.summary()
| Dep. Variable: | ES_Lab | R-squared: | 0.873 |
|---|---|---|---|
| Model: | OLS | Adj. R-squared: | 0.872 |
| Method: | Least Squares | F-statistic: | 621.6 |
| Date: | Mon, 13 Oct 2025 | Prob (F-statistic): | 0.00 |
| Time: | 11:07:15 | Log-Likelihood: | -3591.7 |
| No. Observations: | 916 | AIC: | 7205. |
| Df Residuals: | 905 | BIC: | 7258. |
| Df Model: | 10 | ||
| Covariance Type: | nonrobust |
| coef | std err | t | P>|t| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| Intercept | -20.2008 | 3.196 | -6.320 | 0.000 | -26.474 | -13.928 |
| Weekday[T.Monday] | -0.6513 | 1.519 | -0.429 | 0.668 | -3.632 | 2.329 |
| Weekday[T.Saturday] | -0.3169 | 1.522 | -0.208 | 0.835 | -3.305 | 2.671 |
| Weekday[T.Sunday] | 0.5073 | 1.524 | 0.333 | 0.739 | -2.483 | 3.498 |
| Weekday[T.Thursday] | -0.4597 | 1.519 | -0.303 | 0.762 | -3.441 | 2.522 |
| Weekday[T.Tuesday] | 1.1055 | 1.518 | 0.728 | 0.467 | -1.875 | 4.085 |
| Weekday[T.Wednesday] | -0.3329 | 1.520 | -0.219 | 0.827 | -3.315 | 2.650 |
| TMK | 1.8619 | 0.218 | 8.557 | 0.000 | 1.435 | 2.289 |
| SDK | 7.0105 | 0.189 | 37.032 | 0.000 | 6.639 | 7.382 |
| NM | 3.5985 | 0.349 | 10.310 | 0.000 | 2.914 | 4.284 |
| VPM | -1.4871 | 0.322 | -4.616 | 0.000 | -2.119 | -0.855 |
| Omnibus: | 36.205 | Durbin-Watson: | 1.115 |
|---|---|---|---|
| Prob(Omnibus): | 0.000 | Jarque-Bera (JB): | 77.580 |
| Skew: | -0.219 | Prob(JB): | 1.42e-17 |
| Kurtosis: | 4.357 | Cond. No. | 147. |
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
Vergleichen wir die Qualität beider Modelle
from sklearn.metrics import mean_absolute_error, r2_score
r2_score(egywthN.ES_Lab, egywthN.ols), mean_absolute_error(egywthN.ES_Lab, egywthN.ols)
(0.872909238506527, 9.23873213104902)
r2_score(egywthN.ES_Lab, egywthN.gam), mean_absolute_error(egywthN.ES_Lab, egywthN.gam)
(0.8822826884210837, 8.86976988402153)
so sehen wir das das GAM-Modell etwas besser ist, aber nicht deutlich. Das zeigt sich auch im Plot.
fig=px.line(egywthN, x="Date", y=["ES_Lab", "ols", "gam"])
fig.show()
ARMA - Autoregressive Moving Average#
Ein Aspekt den wir bisher in unserem Datensatz ignoriert haben, ist die Tatsache, dass es sich bei der Energie um eine Zeitreihe handelt und wir im Linien-Diagramm bereits beobachtet haben, dass Werte sehr stark vom Vorgängerwert abhängen. Diese Abhängigkeit bezeichnet man als Autoregression. Um diese Autoregression zu modellieren, gibt es spezielle Modelle. Ein sehr typisches Modell ist das ARIMA-Modell. Es gleicht einem Linearem Regressionsmodell, das als Eingang bis zu \(p\) vergangenen Zielwerte \(y_{i-k}\) für \(0<k<p\) betrachtet als auch die \(q\) früheren Vorhersagefehler \(\varepsilon_{i-j}\) integriert.
Hierbei ist das AR-Modell ein Modell das mit den Koeffizient \(a_k\) den Einfluss des \(k\)-ten vergangenen Werts \(y_{i−k}\) auf den aktuellen Wert \(y_i\) darstellt. Das MA-Modell modelliert die Abweichung vom gleitenden Durchschnitt in Form der vergangenen Fehlerterme \(\varepsilon_{i−k}\). Die Ordnungen \(p\) und \(q\) können bestimmt werden durch Analyse der Autokorrelationsfunktion (ACF) zur Bestimmung der Ordnung \(q\) des MA-Teils und der Partielle Autokorrelationsfunktion (PACF) zur Bestimmung der Ordnung \(p\) des AR-Teils.
Ein ARMA-Modell kann erstellt werden mit dem ARIMA-Modul von Statsmodels. Wichtig ist hierbei, dass wir einen äquidistanten Zeitreihe mit einer festen Abtastrate nutzen, auch wenn dieser fehlende Werte enthält, da wir ja die Vorgängerwerte mit betrachten.
from statsmodels.tsa.arima.model import ARIMA
arma_mod = ARIMA(egywth.ES_Lab, order=(8, 0, 1), trend="n")
arma_res = arma_mod.fit()
egywth["arma"]=arma_res.predict()
arma_res.summary()
| Dep. Variable: | ES_Lab | No. Observations: | 1098 |
|---|---|---|---|
| Model: | ARIMA(8, 0, 1) | Log Likelihood | -4618.230 |
| Date: | Mon, 13 Oct 2025 | AIC | 9256.460 |
| Time: | 11:07:17 | BIC | 9306.472 |
| Sample: | 0 | HQIC | 9275.381 |
| - 1098 | |||
| Covariance Type: | opg |
| coef | std err | z | P>|z| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| ar.L1 | 0.9694 | 0.087 | 11.204 | 0.000 | 0.800 | 1.139 |
| ar.L2 | -0.0496 | 0.045 | -1.110 | 0.267 | -0.137 | 0.038 |
| ar.L3 | -0.0416 | 0.039 | -1.075 | 0.282 | -0.117 | 0.034 |
| ar.L4 | -0.0114 | 0.038 | -0.305 | 0.761 | -0.085 | 0.062 |
| ar.L5 | 0.0115 | 0.037 | 0.312 | 0.755 | -0.061 | 0.084 |
| ar.L6 | 0.0597 | 0.037 | 1.634 | 0.102 | -0.012 | 0.131 |
| ar.L7 | -0.0106 | 0.037 | -0.291 | 0.771 | -0.082 | 0.061 |
| ar.L8 | 0.0671 | 0.035 | 1.908 | 0.056 | -0.002 | 0.136 |
| ma.L1 | -0.6439 | 0.088 | -7.343 | 0.000 | -0.816 | -0.472 |
| sigma2 | 297.2980 | 9.665 | 30.761 | 0.000 | 278.356 | 316.240 |
| Ljung-Box (L1) (Q): | 0.00 | Jarque-Bera (JB): | 310.11 |
|---|---|---|---|
| Prob(Q): | 0.96 | Prob(JB): | 0.00 |
| Heteroskedasticity (H): | 0.87 | Skew: | -0.56 |
| Prob(H) (two-sided): | 0.19 | Kurtosis: | 5.35 |
Warnings:
[1] Covariance matrix calculated using the outer product of gradients (complex-step).
Wenn wir das Modell vergleichen mit den vorherigen Modellen, so ist das Vorhersagemodell schlechter und im Diagramm zeigt sich, dass die Vorhersagen geglätteter sind. Allerdings bemötigt das Modell auch keine weitere externen Eingangsvariablen.
egywthN=egywth.dropna()
r2_score(egywthN.ES_Lab, egywthN.arma), mean_absolute_error(egywthN.ES_Lab, egywthN.arma)
(0.7671305047800461, 11.297525602528188)
fig=px.line(egywthN, x="Date", y=["ES_Lab", "arma"])
fig.show()
Autoregressive Lineare und GAM Modelle#
Wir können auch in unsere bisherigen Modelle die Autoregressive Komponente integrieren, indem wir uns eine verschobene Zielvariable definieren. Da wir wissen, dass es auch einen wöchentlichen Saison gibt, fügen wir auch den 7-Tage Lag hinzu.
egywth["ES_Lab1"]=egywth.ES_Lab.shift(-1)
egywth["ES_Lab7"]=egywth.ES_Lab.shift(-7)
egywth.head()
| Date | EV_HT_740 | EV_NT_740 | E_AV_Lab | E_SV_Lab | ES_Lab | DATUM_DT | STATIONS_ID | MESS_DATUM | QN_3 | ... | TGK | eor | TemperaturKlasse | HeizKuehlTage | QNS_4 | QNF_4 | Weekday | arma | ES_Lab1 | ES_Lab7 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2020-12-30 00:00:00+00:00 | NaN | NaN | NaN | NaN | NaN | 2020-12-30 00:00:00+00:00 | 4271.0 | 20201230.0 | 10.0 | ... | 2.2 | eor | Cold | Heizgradtag | nicht alle Parameter korrigiert | 5 | Wednesday | 0.000000 | 5.0 | 3.0 |
| 1 | 2020-12-31 00:00:00+00:00 | NaN | NaN | 1256.0 | 291.0 | 5.0 | 2020-12-31 00:00:00+00:00 | 4271.0 | 20201231.0 | 10.0 | ... | 0.9 | eor | Cold | Heizgradtag | nicht alle Parameter korrigiert | 5 | Thursday | 0.000000 | 1.0 | 2.0 |
| 2 | 2021-01-01 00:00:00+00:00 | 0.0 | 4080.0 | 1221.0 | 290.0 | 1.0 | 2021-01-01 00:00:00+00:00 | 4271.0 | 20210101.0 | 10.0 | ... | 0.3 | eor | Cold | Heizgradtag | nicht alle Parameter korrigiert | 5 | Friday | 4.538884 | 2.0 | 2.0 |
| 3 | 2021-01-02 00:00:00+00:00 | 1170.0 | 2630.0 | 1243.0 | 284.0 | 2.0 | 2021-01-02 00:00:00+00:00 | 4271.0 | 20210102.0 | 10.0 | ... | 2.0 | eor | Cold | Heizgradtag | nicht alle Parameter korrigiert | 5 | Saturday | 2.540173 | 2.0 | 3.0 |
| 4 | 2021-01-03 00:00:00+00:00 | 0.0 | 3750.0 | 1222.0 | 283.0 | 2.0 | 2021-01-03 00:00:00+00:00 | 4271.0 | 20210103.0 | 10.0 | ... | 0.8 | eor | Cold | Heizgradtag | nicht alle Parameter korrigiert | 5 | Sunday | 2.280147 | 5.0 | 9.0 |
5 rows × 34 columns
import statsmodels.formula.api as smf
egywthN=egywth.dropna().copy()
smflmAR = smf.ols("ES_Lab ~ TMK + SDK + NM + VPM + Weekday + ES_Lab1 + ES_Lab7", data=egywthN).fit()
egywthN["olsAR"]=smflmAR.predict()
smflmAR.summary()
| Dep. Variable: | ES_Lab | R-squared: | 0.934 |
|---|---|---|---|
| Model: | OLS | Adj. R-squared: | 0.933 |
| Method: | Least Squares | F-statistic: | 1051. |
| Date: | Mon, 13 Oct 2025 | Prob (F-statistic): | 0.00 |
| Time: | 11:07:18 | Log-Likelihood: | -3242.5 |
| No. Observations: | 903 | AIC: | 6511. |
| Df Residuals: | 890 | BIC: | 6574. |
| Df Model: | 12 | ||
| Covariance Type: | nonrobust |
| coef | std err | t | P>|t| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| Intercept | -16.8304 | 2.345 | -7.176 | 0.000 | -21.433 | -12.227 |
| Weekday[T.Monday] | -0.7007 | 1.103 | -0.635 | 0.525 | -2.865 | 1.464 |
| Weekday[T.Saturday] | -0.8303 | 1.103 | -0.753 | 0.452 | -2.994 | 1.334 |
| Weekday[T.Sunday] | -0.1096 | 1.108 | -0.099 | 0.921 | -2.283 | 2.064 |
| Weekday[T.Thursday] | -0.1587 | 1.104 | -0.144 | 0.886 | -2.325 | 2.007 |
| Weekday[T.Tuesday] | 0.2843 | 1.103 | 0.258 | 0.797 | -1.880 | 2.449 |
| Weekday[T.Wednesday] | 0.1509 | 1.105 | 0.137 | 0.891 | -2.019 | 2.320 |
| TMK | 1.0641 | 0.160 | 6.661 | 0.000 | 0.751 | 1.378 |
| SDK | 5.2692 | 0.153 | 34.430 | 0.000 | 4.969 | 5.570 |
| NM | 2.6722 | 0.260 | 10.276 | 0.000 | 2.162 | 3.183 |
| VPM | -1.1198 | 0.233 | -4.811 | 0.000 | -1.577 | -0.663 |
| ES_Lab1 | 0.2399 | 0.016 | 15.343 | 0.000 | 0.209 | 0.271 |
| ES_Lab7 | 0.1472 | 0.014 | 10.384 | 0.000 | 0.119 | 0.175 |
| Omnibus: | 27.485 | Durbin-Watson: | 1.835 |
|---|---|---|---|
| Prob(Omnibus): | 0.000 | Jarque-Bera (JB): | 62.194 |
| Skew: | -0.085 | Prob(JB): | 3.12e-14 |
| Kurtosis: | 4.275 | Cond. No. | 624. |
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
bs = BSplines(egywthN[['TMK', "SDK", "NM", "VPM", "ES_Lab1", "ES_Lab7"]], df=[4, 4, 4, 4, 4, 4], degree=[3, 3, 3, 3, 3, 3])
# Fit the GAM model
smfgamAR = GLMGam.from_formula(formula="ES_Lab ~ TMK + SDK + NM + VPM + Weekday + ES_Lab1 + ES_Lab7", data=egywthN, smoother=bs)
smfgamAR = smfgamAR.fit()
egywthN["gamAR"]=smfgamAR.predict()
smfgamAR.summary()
| Dep. Variable: | ES_Lab | No. Observations: | 903 |
|---|---|---|---|
| Model: | GLMGam | Df Residuals: | 878 |
| Model Family: | Gaussian | Df Model: | 24.00 |
| Link Function: | Identity | Scale: | 72.947 |
| Method: | PIRLS | Log-Likelihood: | -3205.4 |
| Date: | Mon, 13 Oct 2025 | Deviance: | 64047. |
| Time: | 11:07:18 | Pearson chi2: | 6.40e+04 |
| No. Iterations: | 3 | Pseudo R-squ. (CS): | 1.000 |
| Covariance Type: | nonrobust |
| coef | std err | z | P>|z| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| Intercept | -17.4815 | 3.362 | -5.199 | 0.000 | -24.071 | -10.892 |
| Weekday[T.Monday] | -0.5792 | 1.067 | -0.543 | 0.587 | -2.670 | 1.512 |
| Weekday[T.Saturday] | -0.8967 | 1.069 | -0.839 | 0.402 | -2.992 | 1.198 |
| Weekday[T.Sunday] | 0.2925 | 1.074 | 0.272 | 0.785 | -1.812 | 2.397 |
| Weekday[T.Thursday] | -0.1385 | 1.070 | -0.129 | 0.897 | -2.236 | 1.959 |
| Weekday[T.Tuesday] | -0.0400 | 1.071 | -0.037 | 0.970 | -2.138 | 2.058 |
| Weekday[T.Wednesday] | -0.3121 | 1.077 | -0.290 | 0.772 | -2.422 | 1.798 |
| TMK | 1.1854 | 0.216 | 5.486 | 0.000 | 0.762 | 1.609 |
| SDK | 5.2207 | 0.160 | 32.706 | 0.000 | 4.908 | 5.534 |
| NM | 3.0381 | 0.338 | 8.990 | 0.000 | 2.376 | 3.701 |
| VPM | -1.1884 | 0.316 | -3.765 | 0.000 | -1.807 | -0.570 |
| ES_Lab1 | 0.2497 | 0.019 | 13.071 | 0.000 | 0.212 | 0.287 |
| ES_Lab7 | 0.1443 | 0.017 | 8.379 | 0.000 | 0.111 | 0.178 |
| TMK_s0 | 2.2618 | 6.956 | 0.325 | 0.745 | -11.372 | 15.896 |
| TMK_s1 | -0.8353 | 6.335 | -0.132 | 0.895 | -13.252 | 11.582 |
| TMK_s2 | -3.0084 | 3.335 | -0.902 | 0.367 | -9.544 | 3.527 |
| SDK_s0 | -14.7653 | 2.520 | -5.859 | 0.000 | -19.705 | -9.826 |
| SDK_s1 | -0.7000 | 3.237 | -0.216 | 0.829 | -7.044 | 5.644 |
| SDK_s2 | 5.7120 | 1.733 | 3.295 | 0.001 | 2.314 | 9.110 |
| NM_s0 | -3.2865 | 3.552 | -0.925 | 0.355 | -10.247 | 3.674 |
| NM_s1 | 7.0927 | 2.172 | 3.265 | 0.001 | 2.835 | 11.351 |
| NM_s2 | -3.2532 | 1.038 | -3.135 | 0.002 | -5.287 | -1.220 |
| VPM_s0 | 1.2826 | 6.374 | 0.201 | 0.841 | -11.210 | 13.775 |
| VPM_s1 | -6.0830 | 4.893 | -1.243 | 0.214 | -15.673 | 3.507 |
| VPM_s2 | 5.8977 | 2.386 | 2.471 | 0.013 | 1.220 | 10.575 |
| ES_Lab1_s0 | 5.8210 | 3.137 | 1.856 | 0.064 | -0.327 | 11.969 |
| ES_Lab1_s1 | -0.5841 | 3.122 | -0.187 | 0.852 | -6.704 | 5.536 |
| ES_Lab1_s2 | -1.5488 | 1.537 | -1.008 | 0.314 | -4.561 | 1.464 |
| ES_Lab7_s0 | 0.1835 | 2.923 | 0.063 | 0.950 | -5.546 | 5.913 |
| ES_Lab7_s1 | 0.4058 | 2.878 | 0.141 | 0.888 | -5.236 | 6.047 |
| ES_Lab7_s2 | -0.3305 | 1.414 | -0.234 | 0.815 | -3.102 | 2.441 |
Die resultierenden Modelle sind durch Hinzufügen der autoregressiven Komponente deutlich besser. Es erfordert allerdings eine äquidistante Zeitreihe da sonst Abhängigkeiten inkorrekt aufgelöst werden.
r2_score(egywthN.ES_Lab, egywthN.olsAR), mean_absolute_error(egywthN.ES_Lab, egywthN.olsAR)
(0.9341028559113053, 6.484963670842139)
r2_score(egywthN.ES_Lab, egywthN.gamAR), mean_absolute_error(egywthN.ES_Lab, egywthN.gamAR)
(0.9392984503858443, 6.149861158597457)
Auch zeigt sich das bei den täglichen Werten das einfache Lineare Modell bereits gut genug ist und das komplexere GAM-Modell nicht besser abschneidet. Das ist jedoch nicht zu verallgemeinern, sondern kann sich stark nach Datensatz unterscheiden.
fig=px.line(egywthN, x="Date", y=["ES_Lab", "olsAR", "gamAR"])
fig.show()