Clustern#

A city, far from being a cluster of buildings, is actually a sequence of spaces enclosed and defined by buildings.
— Ieoh Ming Pei
Die wichtigste Aufgabe im Unsupervised Learning ist das Cluster. Clustern ist eine Technik des maschinellen Lernens, mit der Datenpunkte in Gruppen (Cluster) mit ähnlichen Eigenschaften zusammengefasst werden. Typische Anwendungen für Clustering sind zum Beispiel für die Kundensegmentierung, die Betrugserkennung und die Bildverarbeitung.
Es gibt unterschiedliche Typen von Clustering-Verfahren, die je nach Zielsetzung und Eigenschaften der Daten geeignet sind. Wir werden konkreten Verfahren von einige davon im Folgenden näher betrachten:
Partitionierende Verfahren teilen die Daten in eine feste Anzahl von Clustern und versuchen, die Varianz innerhalb der Cluster zu minimieren.
Hierarchische Verfahren bauen eine Clusterhierarchie auf und sind flexibler, benötigen jedoch mehr Berechnungsressourcen.
Dichtebasierte Verfahren identifizieren Cluster basierend auf der Dichte der Datenpunkte und sind besonders gut für Daten mit Rauschen und Clustern unregelmäßiger Form geeignet.
Gitterbasierte Verfahren teilen den Datenraum in eine endliche Anzahl von Zellen (Gitter) und führen das Clustering auf diesen Zellen durch.
Graphbasierte Verfahren nutzen Graphstrukturen, um die Ähnlichkeiten zwischen den Datenpunkten darzustellen und das Clustering durchzuführen.
Möchtest du z.B. verschiedene Gebäudetypen anhand ihres Energieverbrauchs clustern, kannst du mit einem partitionierenden Verfahren wie \(k\)-Means eine feste Anzahl von Verbrauchsmustern identifizieren. Wenn hingegen Sensoren im Untergrund punktuell Werte melden, können dichtebasierte Verfahren helfen, Cluster instabiler Zonen (z. B. bei Rutschgefahr) zu erkennen – auch bei unregelmäßiger Datenverteilung.
Folien#
Partitionierende Clustering - \(k\)-means#
Methode#
\(k\)-Means ist ein weit verbreiteter Algorithmus zur partiellen Gruppierung von Datenpunkten in eine vordefinierte Anzahl \(k\) von Clustern aufzuteilen. Der Algorithmus ist zum sehr beliebt, weil er einfach zu verstehen ist und auch bei großen Datensätzen sehr schnell rechnet.
Der Algorithmus versucht, die Summe der quadratischen Abstände zwischen den Datenpunkten und ihren jeweiligen Clusterzentren zu minimieren:
Dabei geht der Algorithmus wie folgt vor:
Initialisierung: Wähle \(k\) Initialwerte für die Clusterzentren (meist zufällig).
Zuordnung: Weise jeden Datenpunkt \( x_i \) dem nächstgelegenen Clusterzentrum \( \mu_j \) zu:
\[ C_j = \{ x_i : \| x_i - \mu_j \|^2 \leq \| x_i - \mu_z \|^2 \quad \forall z, 1 \leq z \leq k \} \]Aktualisierung: Berechne die neuen Clusterzentren als Mittelwert der zugewiesenen Punkte:
\[ \mu_j = \frac{1}{|C_j|} \sum_{x_i \in C_j} x_i \]Wiederholung: Wiederhole die Schritte 2 und 3, bis die Clusterzentren konvergieren (d.h., sie ändern sich nicht mehr signifikant).
\(k\)-Means eignet sich am besten für Cluster mit sphärischer Form. In anderen Fällen kann die Qualität der Cluster suboptimal sein. Durch die zufällige Initialisierung können die Ergebnisse von \(k\)-Means von der Wahl der initialen Clusterzentren abhängen, weshalb es sich lohnt \(k\)-Means ggf. mehrmals auszuführen und gute Clusterzentren zu speichern.
Einfaches Beispiel#
Clustering wird am besten in einem 2-D-Rahmen verstanden, in dem wir die Daten und Cluster leicht visualisieren können. Das haben wir schon bei der Klassifikation mit dem Yin-Yang Datensatz gemacht. Der eignet sich für das Clustering nicht, da beide Klassen nicht klar getrennt sind und somit durch Clustering nicht zu identifizieren wären.
Deshalb erzeugen wir uns zuerst ein einfaches Beispiel mit 5 Clustern. Als ersten Schritt erstellen wir zufällig die entsprechenden Clusterzentren \(x_{1c}\) und \(x_{2c}\) aus einer Normalverteilung mit einer Standardabweichung (scale) von 5.
import numpy as np # Import von NumPy
import pandas as pd # Import von Pandas
import plotly.express as px # Import von Plotly
px.set_mapbox_access_token(open(".mapbox_token").read())
nc = 5 # number of clusters
np.random.seed(1) # make the results replicable
## create cluster centers
x1c = np.random.normal(scale=5, size=nc)
x2c = np.random.normal(scale=5, size=nc)
---------------------------------------------------------------------------
FileNotFoundError Traceback (most recent call last)
Cell In[1], line 4
2 import pandas as pd # Import von Pandas
3 import plotly.express as px # Import von Plotly
----> 4 px.set_mapbox_access_token(open(".mapbox_token").read())
6 nc = 5 # number of clusters
7 np.random.seed(1) # make the results replicable
File /opt/hostedtoolcache/Python/3.11.0/x64/lib/python3.11/site-packages/IPython/core/interactiveshell.py:343, in _modified_open(file, *args, **kwargs)
336 if file in {0, 1, 2}:
337 raise ValueError(
338 f"IPython won't let you open fd={file} by default "
339 "as it is likely to crash IPython. If you know what you are doing, "
340 "you can use builtins' open."
341 )
--> 343 return io_open(file, *args, **kwargs)
FileNotFoundError: [Errno 2] No such file or directory: '.mapbox_token'
Als nächstes erstellen wir 100 Datenpunkte. Wir weisen jedem Datenpunkt einem Cluster zu und platzieren ihn dann in einer zufälligen Position in der Nähe des entsprechenden Clusterzentrums. Die Cluster könnten sinnvolle IDs haben, aber hier weisen wir ihnen einfach ein numerisches Label \(0, 1, \dots, 4\) zu.
n = 100 # number of data points
cl = np.random.choice(nc, n) # cluster membership label for each dot
## create clusters around centers
x1 = x1c[cl] + np.random.normal(size=n)
x2 = x2c[cl] + np.random.normal(size=n)
df = pd.DataFrame({"x1":x1, "x2":x2, "cluster":cl})
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
Cell In[2], line 2
1 n = 100 # number of data points
----> 2 cl = np.random.choice(nc, n) # cluster membership label for each dot
3 ## create clusters around centers
4 x1 = x1c[cl] + np.random.normal(size=n)
NameError: name 'nc' is not defined
Die Variable cl ist die ID (numerisches Label) des entsprechenden Clusters, die zufällig mit np.random.choice ausgewählt wird. Beachten Sie, wie die Punkte \((x, y)\) in der Nähe des entsprechenden Clusterzentrums \((x_{1c}, x_{2c})\) platziert sind, während zusätzliches normales Rauschen hinzugefügt wird. Allerdings hat diese Zeitskala ihren Standardwert, d.h. die Standardabweichung des Rauschens beträgt 1. Daher sind die Datenpunkte im Vergleich zu den Zentren selbst viel weniger um das Clusterzentrum herum verteilt.
Es gibt fünf verschiedene Cluster, die hier je nach entsprechender Cluster-ID unterschiedlich eingefärbt sind. Der vertikale und horizontale Maßstab ist gleich, damit das menschliche Auge die Entfernung richtig einschätzen kann, die wir unten verwenden.
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
Cell In[3], line 1
----> 1 fig=px.scatter(df, x="x1", y="x2", color="cluster", opacity=0.5, width=600, height=600)
2 fig.update_coloraxes(showscale=False)
3 fig.show()
NameError: name 'df' is not defined
Die Verwendung von unüberwachten Methoden in sklearn ist in vielerlei Hinsicht ähnlich wie die Verwendung von überwachten Methoden, mit der Ausnahme, dass das Anpassen des Modells ohne das Ziel y erfolgen muss. Wir importieren KMeans aus sklearn.cluster wie gewohnt. Danach richten wir das Modell ein, indem wir einfach KMeans() aufrufen. Das wichtigste Argument, das erwartet wird, ist die Anzahl der Cluster \(k\). Es gibt auch andere Optionen in Bezug auf die Iterationen (max_iter), den genauen Algorithmus (algorithm). Als nächstes erstellen wir die Designmatrix \(\bar{X}\), die wir unten für die Anpassung benötigen. Danach passen wir das Modell mit fit an, beachten Sie, dass wir für das unüberwachte Modell nur die Designmatrix X und keine Zielvariable y angeben (es ist ja einen unsupervised Model):
from sklearn.cluster import KMeans
X = df[['x1','x2']]
m = KMeans(n_clusters=5)
m.fit(X)
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
Cell In[4], line 3
1 from sklearn.cluster import KMeans
----> 3 X = df[['x1','x2']]
5 m = KMeans(n_clusters=5)
6 m.fit(X)
NameError: name 'df' is not defined
Dies erstellt das angepasste Modell, das wir in den nächsten Schritten zur Vorhersage von Cluster-Labels mit predict() verwenden können.
df['pred'] = m.predict(X) # predicted cluster membership for each dot
df['pred'].head()
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
Cell In[5], line 1
----> 1 df['pred'] = m.predict(X) # predicted cluster membership for each dot
2 df['pred'].head()
NameError: name 'm' is not defined
Die Methode predict berechnet das vorhergesagte Cluster-Label für jede Beobachtung (in X), wobei der mögliche Label-Bereich von \(0\) bis \(k-1\) reicht. Die identifizierte Cluster-Zentren können mit dem Attribut cluster_centers_ abgefragt werden:
hatc = m.cluster_centers_ # centroids for each cluster
print("centers:\n", hatc)
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
Cell In[6], line 1
----> 1 hatc = m.cluster_centers_ # centroids for each cluster
2 print("centers:\n", hatc)
NameError: name 'm' is not defined
Dies gibt \(k\) (hier 5) Vektoren zurück (als Zeilen der Matrix). Jeder Vektor entspricht den Schwerpunkten (Centroid) der entsprechenden Cluster, in der gleichen Reihenfolge wie die Labels. Die erste Zeile der Matrix ist also der Schwerpunkt für Cluster “0”. Da die Daten hier 2-dimensional sind, enthalten die Schwerpunkte zwei Komponenten.
Es ist ziemlich einfach, die Ergebnisse von \(k\)-means zu visualisieren:
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
Cell In[7], line 1
----> 1 fig = px.scatter(df, x="x1", y="x2", color="pred", opacity=0.5, width=600, height=600)
2 fig.add_scatter(x=hatc[:,0], y=hatc[:,1], mode="markers", marker = dict(symbol = 'circle-open-dot', size=20), name="center")
3 fig.update_coloraxes(showscale=False)
NameError: name 'df' is not defined
Wahl der Anzahl der Cluster \(k\)#
Die Herausforderung bei \(k\)-Means-Clustering ist den Parameter \(k\) gut zu wählen. Hierbei möchte man zum einen sicherstellen, dass die Cluster gut separiert sind, aber auch nicht so groß, dass zu viele kaum separierte Untercluster entstehen. Visualisieren wir einmal die Ergebnisse für 3 und 10 Cluster.
m = KMeans(n_clusters=3).fit(X)
hatc2 = m.cluster_centers_
df['pred2'] = m.predict(X)
fig = px.scatter(df, x="x1", y="x2", color="pred2", opacity=0.5, width=600, height=600)
fig.add_scatter(x=hatc2[:,0], y=hatc2[:,1], mode="markers", marker = dict(symbol = 'circle-open-dot', size=20), name="center")
fig.update_coloraxes(showscale=False)
fig.show()
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
Cell In[8], line 1
----> 1 m = KMeans(n_clusters=3).fit(X)
2 hatc2 = m.cluster_centers_
3 df['pred2'] = m.predict(X)
NameError: name 'X' is not defined
m = KMeans(n_clusters=10).fit(X)
hatc2 = m.cluster_centers_
df['pred2'] = m.predict(X)
fig = px.scatter(df, x="x1", y="x2", color="pred2", opacity=0.5, width=600, height=600)
fig.add_scatter(x=hatc2[:,0], y=hatc2[:,1], mode="markers", marker = dict(symbol = 'circle-open-dot', size=20), name="center")
fig.update_coloraxes(showscale=False)
fig.show()
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
Cell In[9], line 1
----> 1 m = KMeans(n_clusters=10).fit(X)
2 hatc2 = m.cluster_centers_
3 df['pred2'] = m.predict(X)
NameError: name 'X' is not defined
Um ein geeignetes \(k\) zu identifizieren kann man so genannte Ellbogen-Diagramme erzeugen, indem man einfach mehrere Cluster mit unterschiedlichen \(k\)-Werten trainiert und den quadratischen Fehler (inertia_). Wenn man diese Fehler als Linien-Diagramm darstellt ergibt sich eine abfallende Funktion, die einem Ellbogen ähnlich ist. Die besten \(k\)-Werte liegen dort wo die Kurve abflacht. In diesem Beispiel nicht überraschend bei 5.
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
Cell In[10], line 2
1 k_range = range(2, 10) # Clusteranzahl
----> 2 loss = [KMeans(k).fit(X).inertia_ for k in k_range]
4 px.line(x=k_range, y=loss)
Cell In[10], line 2, in <listcomp>(.0)
1 k_range = range(2, 10) # Clusteranzahl
----> 2 loss = [KMeans(k).fit(X).inertia_ for k in k_range]
4 px.line(x=k_range, y=loss)
NameError: name 'X' is not defined
Das Attribut inertia_ des angepassten Modells enthält den entsprechenden Verlustfunktionswert.
Hier passen wir \(k\)-Means-Modelle für \(k = 2, 3, \dots, 9\) an, speichern den jeweiligen Verlust und plotten ihn.
Wir können sehen, dass der Verlust schnell auf fast null fällt bei \(k=5\). Daher ist \(k=5\) die optimale Anzahl von Clustern in diesen Daten. Dies kann tatsächlich visuell auf den obigen Bildern bestätigt werden.
Beispiel Baustellen#
Prüfen wir den Ansatz auf einem echten Datensatz, der Liste an Baustellen in Rostock. Wir wollen die Baustellen nach ihrem Ort clustern, also nach der Latitude und Longitude.
baust = pd.read_csv("../data/Baustellen/baustellen_flat.csv")
baust = baust.dropna(subset=["latitude", "longitude","sparte"])
baust.head(3)
| latitude | longitude | uuid | kreis_name | kreis_schluessel | gemeindeverband_name | gemeindeverband_schluessel | gemeinde_name | gemeinde_schluessel | strasse_name | strasse_schluessel | sparte | von | nach | baubeginn | bauende | verkehrsbeeintraechtigungen | baumassnahme | dauer | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 54.089282 | 12.111994 | 063a229c-db25-45af-9fba-8d963b287910 | Rostock | 13003.0 | Rostock, Hanse- und Universitätsstadt | 130030000.0 | Rostock, Hanse- und Universitätsstadt | 1.300300e+11 | Budapester Str. | 01640 | Fernwärmeleitung | 21 | NaN | 2024-03-04 07:00:00+01:00 | 2024-04-12 17:00:00+02:00 | Sicherungsmaßnahmen entlang der Straße, Verkeh... | FW-Leitung i.a. der Hanseatic | 39.375000 |
| 1 | 54.068210 | 12.078264 | 07165e95-4e5f-429c-88b6-125d261cbcda | Rostock | 13003.0 | Rostock, Hanse- und Universitätsstadt | 130030000.0 | Rostock, Hanse- und Universitätsstadt | 1.300300e+11 | Satower Str. | 08180 | Grünpflege | 56 | 65 | 2024-03-07 07:00:00+01:00 | 2024-03-31 15:00:00+02:00 | halbseitige Sperrung, Sicherungsmaßnahmen entl... | Baumpflanzung | 24.291667 |
| 2 | 54.174303 | 12.081928 | 077f9448-c35e-4074-8491-7d142045a8db | Rostock | 13003.0 | Rostock, Hanse- und Universitätsstadt | 130030000.0 | Rostock, Hanse- und Universitätsstadt | 1.300300e+11 | Am Markt | 00460 | Wasserleitung | 6 | NaN | 2024-03-06 07:00:00+01:00 | 2024-03-28 18:00:00+01:00 | Sicherungsmaßnahmen entlang der Straße, Sicher... | Einbau Trinkwasserschieber | 22.458333 |
Bilden wir als erstes die Designmatrix und visualisieren das Ellbogendiagramm, um eine geeignete Anzahl an Clustern zu identifizieren.
Xb = baust[['latitude','longitude']]
k_range = range(2, 30) # Clusteranzahl
loss = [KMeans(k).fit(Xb).inertia_ for k in k_range]
px.line(x=k_range, y=loss)
/opt/hostedtoolcache/Python/3.11.0/x64/lib/python3.11/site-packages/kaleido/_sync_server.py:11: UserWarning:
Warning: You have Plotly version 5.24.1, which is not compatible with this version of Kaleido (1.1.0).
This means that static image generation (e.g. `fig.write_image()`) will not work.
Please upgrade Plotly to version 6.1.1 or greater, or downgrade Kaleido to version 0.2.1.
Das ist ein typisches, echtes Ellbogendiagramm, wo das beste \(k\) nicht klar erkennbar ist. Allerdings ist der Anstieg für Werte unter 10 noch zu hoch, um nützlich zu sein. Ab 15 flacht die Kurve so ab, dass man hier eine Grenze setzen kann.
Xb = baust[['latitude','longitude']]
mb = KMeans(n_clusters=7)
mb.fit(Xb)
KMeans(n_clusters=7)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Parameters
| n_clusters | 7 | |
| init | 'k-means++' | |
| n_init | 'auto' | |
| max_iter | 300 | |
| tol | 0.0001 | |
| verbose | 0 | |
| random_state | None | |
| copy_x | True | |
| algorithm | 'lloyd' |
baust['pred'] = mb.predict(Xb) # identifizierte cluster
hatcb = mb.cluster_centers_ # centroids for each cluster
fig = px.scatter_mapbox(baust, lat="latitude", lon="longitude", color="pred", hover_name="sparte", zoom=9, width=600, height=600)
fig.add_scattermapbox(lat=hatcb[:,0], lon=hatcb[:,1], mode="markers", name="center")
fig.update_coloraxes(showscale=False).show()
Hierarchisches Clustering#
Hierarchisches Clustern ist eine Methode zur Gruppierung von Datenpunkten, die eine hierarchische Struktur von Clustern erstellt. Es gibt zwei Hauptansätze: agglomerative (bottom-up) und divisive (top-down) Methoden.
Agglomeratives Hierarchisches#
Agglomeratives Hierarchisches Clustering beginnt mit jedem Datenpunkt als eigenständigem Cluster und fusioniert iterativ die nächsten Paare von Clustern, bis nur noch ein Cluster übrigbleibt. Dabei sind die Schritte des agglomerativen Clustering:
Initialisierung: Initialisiere \(n\) Cluster, wobei jeder Cluster einen Datenpunkt enthält.
Entfernungsmessung: Berechne die Distanz zwischen allen Paaren von Clustern unter Nutzung einer der untenstehenden Abstandsmaße.
Fusionierung: Identifiziere die zwei nächsten Cluster unter Nutzung einer der untenstehenden Fusionierungsstrategien. Fasse diese beiden Cluster zu einem neuen Cluster zusammen. Aktualisiere die Distanzen zwischen den Clustern.
Wiederholung: Wiederhole Schritt 2 und 3, bis nur noch die gewünschte Anzahl von Clustern übrig ist.
Hierbei werden unterschiedliche Abstandsmaße verwendet:
Jaccard: Die Jaccard-Distanz wird hauptsächlich für binäre oder kategorische Daten (Text) verwendet. Sie misst die Ähnlichkeit zwischen endlichen Mengen und ist besonders nützlich, wenn es um die Anwesenheit oder Abwesenheit von Merkmalen geht.
Euklidisch: Die Euklidische Distanz ist das am häufigsten verwendete Maß für den Abstand zwischen zwei Punkten in einem \(n\)-dimensionalen Raum. Sie ist besonders nützlich, wenn die Datenpunkte metrisch sind.
Pearson: Die Pearson-Korrelation misst die lineare Korrelation zwischen zwei Variablen und liegt zwischen -1 und 1. Sie ist besonders nützlich, wenn die Beziehung zwischen Variablen linear ist.
Manhattan: Die Manhattan-Distanz, auch City Block Distanz genannt, summiert die absoluten Unterschiede der Koordinaten zweier Punkte. Sie ist besonders nützlich, wenn die Daten eine natürliche Gitterstruktur haben.
und unterschiedliche Fusionierungsstrategien benutzt
Single Linkage misst die minimale Distanz zwischen Punkten in zwei Clustern. Es neigt dazu, längliche und “chainged” Cluster zu erstellen.
Complete Linkage misst die maximale Distanz zwischen Punkten in zwei Clustern. Es erzeugt kompakte und sphärische Cluster.
Average Linkage misst die durchschnittliche Distanz zwischen Punkten in zwei Clustern. Es balanciert zwischen den Extremen von Single und Complete Linkage und ist nützlich, wenn Cluster ähnliche Varianz haben.
Centroid-Linkage misst die Distanz zwischen den Schwerpunkten (Centroide) der Cluster. Es ist nützlich, wenn der Schwerpunkt eines Clusters von Interesse ist. Es kann aber auch zu Problemen führen, wenn Schwerpunkte sich in leere Räume bewegen (Inversionsproblem).
Ward’s Method minimiert die Varianz innerhalb der Cluster. Es ist eine der besten Methoden und fördert die Bildung von kompakten, kugelförmigen Clustern.
Die Verwendung der Modelle ist wie gehabt.
from sklearn.cluster import AgglomerativeClustering
mAHC = AgglomerativeClustering(n_clusters = 5)
df["predAHC"] = mAHC.fit_predict(X)
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
Cell In[16], line 4
1 from sklearn.cluster import AgglomerativeClustering
3 mAHC = AgglomerativeClustering(n_clusters = 5)
----> 4 df["predAHC"] = mAHC.fit_predict(X)
NameError: name 'X' is not defined
Es gibt jedoch einen deutlichen Unterschied: Das Modell AgglomerativeClustering hat keine Methode .predict. Man sollte stattdessen .fit_predict verwenden, da dies sowohl das Anpassen als auch das Vorhersagen in einem Schritt durchführt.
fig=px.scatter(df, x="x1", y="x2", color="predAHC", opacity=0.5, width=600, height=600)
fig.update_coloraxes(showscale=False).show()
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
Cell In[17], line 1
----> 1 fig=px.scatter(df, x="x1", y="x2", color="predAHC", opacity=0.5, width=600, height=600)
2 fig.update_coloraxes(showscale=False).show()
NameError: name 'df' is not defined
Basierend auf diesen Daten sind die hierarchischen Cluster genau die gleichen wie beim \(k\)-means (nur ihre Labels können sich unterscheiden). Das liegt daran, dass die Daten so sauber in verschiedene Cluster aufgeteilt sind, und daher alle Clustering-Algorithmen die gleiche Struktur erkennen werden.
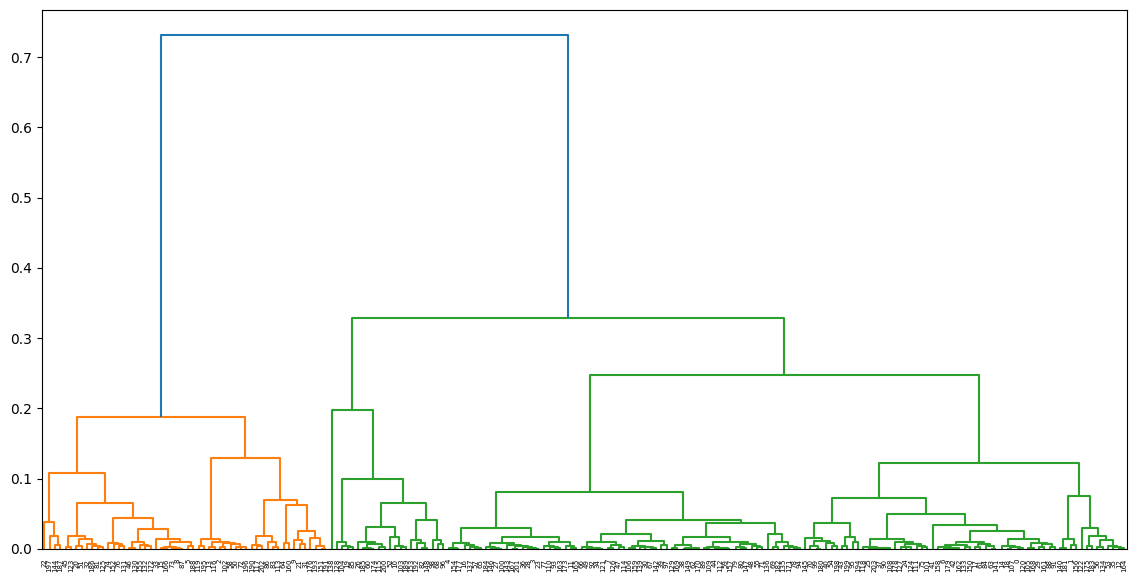
Allerdings ermöglicht hierarchisches Clustering die Anzeige von Dendrogrammen. Dies ist eine Baum-Darstellung des Hierarchischen Cluster. Das wichtige dabei ist, dass die Höhe der Äste zwischen Knoten die Distanz beider Cluster anzeigt. Je länger der Ast, desto größer ist die Distanz zwischen den vereinigten Clustern. Dadurch lassen sich auch gut die passende Anzahl \(n\) an Clustern schätzen.
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
Cell In[18], line 5
2 import scipy.cluster.hierarchy as sch
4 plt.figure(figsize=(14, 7))
----> 5 dendrogram = sch.dendrogram((sch.linkage(X, method='ward')))
NameError: name 'X' is not defined
<Figure size 1400x700 with 0 Axes>
Versuchen wir den Clusteringansatz auf dem Baustellendatensatz:
mbAHC = AgglomerativeClustering(n_clusters = 15)
baust["predAHC"] = mbAHC.fit_predict(Xb)
mAHC = AgglomerativeClustering(n_clusters = 5)
df["predAHC"] = mAHC.fit_predict(X)
fig = px.scatter_mapbox(baust, lat="latitude", lon="longitude", color="predAHC", hover_name="sparte", zoom=9, width=600, height=600)
fig.update_coloraxes(showscale=False).show()
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
Cell In[20], line 2
1 mAHC = AgglomerativeClustering(n_clusters = 5)
----> 2 df["predAHC"] = mAHC.fit_predict(X)
4 fig = px.scatter_mapbox(baust, lat="latitude", lon="longitude", color="predAHC", hover_name="sparte", zoom=9, width=600, height=600)
5 fig.update_coloraxes(showscale=False).show()
NameError: name 'X' is not defined
fig = px.scatter(baust, x="latitude", y="longitude", color="predAHC", width=600, height=600)
fig.update_coloraxes(showscale=False).show()
plt.figure(figsize=(14, 7))
dendrogram = sch.dendrogram((sch.linkage(Xb, method='ward')))
plt.show()
Divisives Clustering#
Der Algorithmus für divisives Clustering kann wie folgt beschrieben werden:
Initialisierung: Initialisiere einen einzelnen Cluster, der alle Datenpunkte enthält.
Evaluierung: Bewerte, ob der aktuelle Cluster weiter aufgeteilt werden soll. Dies kann z. B. durch ein statistisches Kriterium erfolgen, z. B. anhand der Intra-Cluster-Varianz.
Aufspaltung: Wenn eine Aufspaltung erforderlich ist, teile den Cluster in zwei neue Cluster. Die Aufteilung kann z. B. durch eine K-Means-Initialisierung erfolgen.
Wiederholung: Wiederhole Schritt 2 und 3, bis die gewünschte Anzahl von Clustern erreicht ist.
Das Problem des Ansatzes ist, dass Divisive Verfahren eine Heuristik brauchen, nach denen die Datensätze gespalten werden, wo meist gleiche Verfahren wie beim agglomerativen Clustering genutzt werden, was zu gleichen Ergebnissen führt und einfacher ist. Deshalb findet der Ansatz wenig Anwendung in der Praxis und ist in sklearn auch nicht implementiert, weshalb er hier nicht weiter betrachtet wird.
Dichtebasiertes Clustering#
DBSCAN - Density-Based Spatial Clustering of Applications with Noise#
DBSCAN ist ein Algorithmus für das dichtebasierte räumliche Clustering, der Datenpunkte in Cluster gruppiert, basierend auf ihrer Dichte im Raum. Im Gegensatz zu anderen Clustering-Algorithmen, bei denen die Anzahl der Cluster im Voraus festgelegt werden muss, kann DBSCAN automatisch die Anzahl und Form der Cluster in den Daten erkennen.
DBSCAN basiert auf der Einteilung des Datensatzes in Kernpunkte, Randpunkte und Rauschen. Kernpunkte bilden die zentralen Punkte der Cluster. Es sind Datenpunkte \(x_i\) mit einer hohen Dichte und mit mindestens \(\text{MinPts}\) Nachbarn in einem Radius \(\epsilon\). Diese Nachbarn werden als Randpunkte bezeichnet und gehören zu den Clustern der Kernpunkte, sofern sie nicht selbst Kernpunkte sind. Alle anderen Datenpunkte haben eine geringe Dichte und werden als Rauschen bezeichnet.
Der Algorithmus durchläuft die Datenpunkte und identifiziert die Kernpunkte und Randpunkte wie folgt:
Initialisierung: Markiere alle Datenpunkte als nicht klassifiziert.
Distanzberechnung: Berechne die Distanz zwischen allen Punkten (z.B. Euklidisch).
Für jeden unbesuchten Punkt \( x_i \):
a. Markiere \( x_i \) als besucht.
b. Bestimme alle Nachbarn im Radius \(\epsilon\) via \( N_\epsilon(x_i) =\{x_i \in X | d(x_i,x_j) \leq \epsilon\} \).
c. Wenn \( |N_\epsilon(x_i)| < \text{MinPts} \): Markiere \( p \) als Rauschen.
d. Sonst: Erstelle einen neuen Cluster \( C_{x_i} \) und füge \( x_i \) als Kernpunkt hinzu. Erweitere den Cluster um alle Nachbarn \(x_j\) in \( N_\epsilon(x_i) \) als Randpunkte, wenn sie selbst keien Kernpunkte sind.
Die Anwendung von DBSCAN auf unseren Testdatensatz läuft bekanntermaßen. Hier kann man die Klassen-Labels an dem Attribut labels_ auslesen.
from sklearn.cluster import DBSCAN
mDB = DBSCAN(eps=3, min_samples=2).fit(X)
df['predDBS'] = mDB.labels_
fig = px.scatter(df, x="x1", y="x2", color="predDBS", opacity=0.5, width=600, height=600)
fig.update_coloraxes(showscale=False).show()
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
Cell In[23], line 3
1 from sklearn.cluster import DBSCAN
----> 3 mDB = DBSCAN(eps=3, min_samples=2).fit(X)
5 df['predDBS'] = mDB.labels_
6 fig = px.scatter(df, x="x1", y="x2", color="predDBS", opacity=0.5, width=600, height=600)
NameError: name 'X' is not defined
Der Ansatz erkennt alle fünf Cluster gut, was nicht überrascht, da es gute Dichteunterschiede gibt. Beim Baustellendatensatz sehen wir allerdings Unterschiede. Wo die anderen Clusteransätze die Baustelle in Graal-Müritz als Ausreißer in einem separaten Cluster gepackt haben (und damit unsere Clusteranzahl reduzieren), landet diese bei DBSCAN im Cluster -1, wird also als Rauschen exkludiert. Der Ansatz ist somit weniger anfällig für solche Ausreißer.
mbDB = DBSCAN(eps=0.01, min_samples=4).fit(Xb)
baust['predAHC'] = mbDB.labels_
fig = px.scatter_mapbox(baust, lat="latitude", lon="longitude", color="predAHC", hover_name="sparte", zoom=9, width=600, height=600)
fig.update_coloraxes(showscale=False).show()
OPTICS - Ordering Points To Identify the Clustering Structure#
Obwohl man bei DBSCAN keine Clusteranzahl angeben muss, ist die Wahl von \(\epsilon\) und \(\text{minPts}\) entscheidend für die Qualität der Cluster und häufig schwierig, da sie unintuitiver sind als die Clusteranzahl \(k\). Dies versucht der OPTICS Algorithmus zu verbessern, in dem verschieden dichte Cluster erkannt werden indem eine hierarchische Darstellung (Erreichbarkeitsdiagramm/Reachability Plot) der Clusterstruktur erzeugt wird. Dadurch können Cluster auf verschiedenen Granularitätsebenen extrahiert werden.
from sklearn.cluster import OPTICS
mOPT = OPTICS().fit(X)
df['predOPT'] = mOPT.labels_
fig = px.scatter(df, x="x1", y="x2", color="predDBS", opacity=0.5, width=600, height=600)
fig.update_coloraxes(showscale=False).show()
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
Cell In[25], line 3
1 from sklearn.cluster import OPTICS
----> 3 mOPT = OPTICS().fit(X)
4 df['predOPT'] = mOPT.labels_
5 fig = px.scatter(df, x="x1", y="x2", color="predDBS", opacity=0.5, width=600, height=600)
NameError: name 'X' is not defined
OPTICS sortiert intern die Cluster in ihrer Dichte, bzw. der Distanz in der Dichte. Das kann in Form eines Erreichbarkeitsdiagramm (Reachability Plot) dargestellt werden, welche sich ähnlich wie Dendrogramme gut eignen die Trennbarkeit von Datensätzen zu untersuchen. In dem Plot werden Cluster als Täler repräsentiert. Ein tiefes Tal bedeutet, dass die Punkte in diesem Bereich eng beieinander liegen, was auf eine höhere Dichte hinweist. Spitzen zwischen den Tälern deuten auf die Trennung zwischen Clustern hin. Hohe Spitzen bedeuten, dass es einen größeren Abstand gibt, um von einem Cluster zum nächsten zu gelangen, was auf eine geringe Dichte oder Rauschen hinweist. Punkte, die isoliert sind, können als Rauschen betrachtet werden.
# Generate reachability plot
reachability = mOPT.reachability_[mOPT.ordering_]
plt.plot(reachability)
plt.title('Reachability plot')
plt.show()
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
Cell In[26], line 2
1 # Generate reachability plot
----> 2 reachability = mOPT.reachability_[mOPT.ordering_]
3 plt.plot(reachability)
4 plt.title('Reachability plot')
NameError: name 'mOPT' is not defined
Hier erkennt man gut die fünf Cluster, die gut separiert sind.
Beim Baustellendatensatz ergeben sich andere Cluster als bei DBSCAN. Die Behandlung von Ausreißern, wie die Baustelle in Graal-Müritz ist jedoch gleich.
mbOPT = OPTICS().fit(Xb)
baust['predOPT'] = mbOPT.labels_
fig = px.scatter_mapbox(baust, lat="latitude", lon="longitude", color="predOPT", hover_name="sparte", zoom=9, width=600, height=600)
fig.update_coloraxes(showscale=False).show()
Das Erreichbarkeitsdiagramm ist in diesem Fall auch wesentlich uneindeutiger, was auf eine schlechte Trennbarkeit der Cluster hindeutet.
# Generate reachability plot
reachability = mbOPT.reachability_[mOPT.ordering_]
plt.plot(reachability)
plt.title('Reachability plot')
plt.show()
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
Cell In[28], line 2
1 # Generate reachability plot
----> 2 reachability = mbOPT.reachability_[mOPT.ordering_]
3 plt.plot(reachability)
4 plt.title('Reachability plot')
NameError: name 'mOPT' is not defined